
安装
Docker安装
1 | docker pull mongo |
导入数据:
1 | ➜ ~ docker cp /Users/guanhang/learning/geektime-mongodb-course-master/dump fa589a35a88d:dump |
普通安装
官网创建Atlas共享集群
本地安装community server
- comunity server download
- 创建目录并添加命令
- 导入数据:数据来源
- 在dump的文件路径下执行mogorestore命令
测试的命令:
1 | > show dbs |
使用compass连接mongo

一、问题收集
1.1 概念
- 什么是BSON
BSON 是MongoDB用来在落盘存储时候或者网络传输时候的底层物理数据模型。如果你是存储引擎开发者或者mongodb驱动程序开发者,你需要从这个层面去了解。如果你是绝大部分的应用开发者或者数据库使用者,你只需要关心JSON
BSON = Binary JSON, 是基于JSON基础上加了一些类型及元数据描述的格式。
1.2 使用相关
mdb适合做数据仓库吗
果是传统用来做星形schema或者雪花schema,不是太合适。如果是用来做现代数仓,类似于大数据那样做大宽表,mongodb可以作为一个选择。我在我自己的类似数仓的平台产品里就用了mongodb。 有一些比较不错的亮点是:横向扩展能力,多结构化数据支持,检索能力,元数据管理等
目前我们游戏中存储的章节数据。一个章节包含多个关卡,一个关卡包含多个脚本数据。 现在的做法是建立三个表来存储章节、关卡和脚本,每个表都有多个字段,通过id建立关联。思考过怎么组合使用,但是存在单独访问某一个脚本或某一个关卡信息的情况,感觉如果组合使用获取这种信息会很麻烦,请问下老师是否应该组合使用?还是用多个表通过id关联更好用呢
如果你大部分的操作是基于脚本和关卡直接操作,那如果用组合的方法不一定是最优的。虽然,MongoDB对嵌套数组的操作支持还是很给力,你可以直接取出关卡或脚本,通过使用projection 过滤字段及不匹配的数组元素。对内嵌数组操作也是可以用到索引的,所以效率也不会太糟糕。
MongoDB 4.2 的新特性通配符索引(Wildcard Indexes)
简单来说,wildcard index对于下面这样的结构: { “_id” : 1, “data” : { “a” : 1728, “b” : 6740, “c” : 6481, “d” : 2066, “e” : 3173 } } 可以一条命令(一个索引)同时对a/b/c/d/e 5个字段做索引 db.wildcardIndex.createIndex({“data.$**”:1}); 甚至你将来在这个子文档里增加新的字段,也会自动索引。这样省去你单独创建很多个索引。 但是。。。性能上有人测试过,这种比单独建每个索引还是要更加耗资源,差不多是两倍。 所以方便的代价是资源的更多消耗
如果我有两个字段a和b,希望对每个文档增加一个字段c=a-b. 试了一下用find. forEach然后每个文档执行一个uodate的话速度非常慢。有什么比较高效的方法吗?
db.test.insert({a: 2, b: 3}) db.test.updateMany({}, [{ $set: { c: { $add: [“$a”, “$b”] } } }])
执行db.oplog.rs.findOne().ts 时,返回值是Timestamp(1574326231, 1)。而我的需求是指获取1574326231,如果想获取1574326231值,有现成的函数吗
Timestamp(1574326231, 1).getTime()
MongoDB锁能否支持行级锁 2. 64G内存的虚拟机 能否设置大于50%的wiredTiger cacheSizeGB
1)MongoDB采用的是MVCC机制,实际效果和行级锁类似。 2)可以的,但是要考虑到mongodb除了缓存以外自身还需要额外内存,所以要适当给操作系统和mongo本身留一些
提前问个索引相关的问题,为何Mongo的索引用B树而不是B+树呢,我理解B+树的最大优点是范围查找,MySQL用的B+树,Mongo也有这个需求啊
MongoDB用的是B+树。 http://source.wiredtiger.com/mongodb-3.4/tune_page_size_and_comp.html
1.3 分布式、高可用相关
为什么副本集说是5个9的高可用
MongoDB复制集在从节点故障时候是不会影响到可用性。在主节点故障,进行选举的时候需要数秒到十几秒,这期间会影响写入。一年有365天x86640秒 ~= 3000多万秒。假设你每个月发生一次主节点故障或者其他问题导致选举,每次影响15秒,那么可用率就是:就是(3000w-12x15) / 3000w ~= 99.9994%
MongoDB 支持multi-master,所有节点可以同时读写数据库吗
在一个复制集群里没有multi-master,但是一个分片集群可以有多个master (primary), 每个分片一个primary这种方式
MongoDB这种复制集模式,在不同的数据中心,这中间的网络延迟比较严重吧,不会影响做复制集的效果吗
在多中心部署的时候要考虑网络延迟,所以一般多活中心只是建议能够接受一定数据延迟的情况下才建议
数据规模达到多大级别需要使用分片机制
分片有3个触发条件:数据量,并发量,以及热数据大小(内存需求)。理论上,任意一个都会触发分片需求。如果只看数据量,单分片一般可以到1-2TB
请问分片集群的chunk分裂阈值有哪些?shard key与chunk的分裂阈值是什么关系?如何避免按shard key做chunk分裂时出现超出chunkSize的chunk块?
这个阈值应该是在80%(64MB * 80%)的时候,就会把块一分为二。
1.4 运维相关
MongoDB支持跨版本升级吗 例如2.x升级到4.x
mongodump / mongorestore的方式可以跨版本,但是跨这么多也要试试才行。
分片集群mongorestore -h 一个数据模板,应该使用mongos连接还是 随便一个复制集的主节点就行
使用mongos
如果在docker容器中布署mongodb,一般容器内存与heap内存的比例大概是个什么比例?
MongoDB 默认会使用60%的系统内存,一般至少也要用到1GB缓存,所以容器至少要给个2GB。
mongodump的时候会给collection加lock吗?
不会加lock。所以mongodump出来的不是一个一致的backup。通常可以加上 –oplog参数来获取一个某个时间点的快照类的备份
对于mongo副本集,如果有多个库,由于单集群达到瓶颈了,我想把一个库迁移出去,有什么方法吗,能达到像mysql主从实现吗?并且切换到新集群控制在切换ip的时间吗?
如果可以停服务,可以用 mongodump -d xxx 方式 如果不能停服,需要用一些工具: 如果在阿里云,可以考虑mongoshake 工具 MongoDB官方有mongomirror工具 我们Tapdata也有一个工具,有免费3个月的使用期,如果只是一次性迁移够用了
使用mongodump去备份db,备份过程中会阻塞insert写入吗?是不是如果不想要一致性备份集,就不上锁,如果想要一致性的备份集,加–oplog参数,也不阻塞insert写入
备份不阻塞,除非你用fsyncLock()
不上锁的话,就用 –oplog
我以前用的mssql,如果一个服务器上有多个数据库,想迁移数据库的时候直接考走对应的数据库文件就好。如果是mongodb,发现没有对应的文件,请问除了把数据导出还有别的办法吗
mongodb 不能这么玩,只能用mongodump 或者 mongoexport,或者用迁移工具
老师好,请问下,想删除多行数据,得对多行数据进行备份,有什么工具可以生成反向语句insert进行备份吗
换一个思路。使用MongoDB Ops Manager可以实现任意时间点恢复 - 比如你3:00执行删除动作,4:00发现有问题想回滚,那么可以使用ops manager 把数据库回到3:00的时候。 类似的事情可以用命令行方式做,但是就不是小项目了。 反向生成insert的没有见过,但是自己实现应该很简单
1.5 对比
和mysql比的写入性能方面优势
按照我个人经验是有明显的优势的。有好几家大厂的兄弟,包括百度,网易,字节都有分享类似的经验。 稍微网络搜一下,都有十倍或者更多的数字。原因:1)MongoDB默认的事务级别比MySQL低2)MongoDB支持的batch 写入模式可以大幅度提升写入速度3)MongoDB默认写到内存就返回,不等落盘
mongodb的动态特性有缺点嘛
schema 管理会复杂, 你不能一下确定这个集合到底是什么结构。解决方案是使用Schema Validation 或者 JSON Schema来定义这个集合的严格结构。 JSON Schema类似于关系数据库的schema,但是不同的是如果你需要修改这个schema的话可以随时更改,理论上也不需要对已有数据做更新或者迁移。
比如在mysql批量插入,一次3000条左右比较合适,性能也不错,如果是mongodb,一次插多少条比较高效
这个没有绝对值,通常和文档大小有关。如果在1KB以内的话,我会推荐用1000左右的batch size
你的DEMO 中,很多数据基本上都是冗余存储到一个collection上面,比如订单中的商品或国家直接存储的是对应的名称,而我们使用MySql 时通常存储的是对应的ID,这样mysql 的查询往往需要join 多张表才能满足用户的查询需求,mongo 这样的冗余存储则不需要,但是这也带来一个问题,就是数据一致性问题,当我需要修改某个商品的名称时对应该商品的所有关联数据都要修改,如果像关系型数据库那样主外键设计,那可能还是需要先设计好对应表之间的关系,并且查询同样要聚合查询,那岂不又失去了MongoDb 的文档灵活性,相比mysql还有那么大的优势吗
你可以打破常规思维考虑。国家的名称你多长时间需要改一次呢?当然,商品名称修改频率会略高一些,但也是低频动作。MongoDB已经提供多表多行事务来保证修改的一致性。另外如果是经常要改的内容,也还是可以按照关系设计,并不是绝对要放到一张表里面。
请问mongdb的使用场景,能否替代mysql,在新增,更新,删除,查询操作上与mysql的效率有什么不一样
mongodb在大部分场景是是和mysql可以互换的,作为一个应用的后台数据库的时候。两者更多是使用习惯上的区别。一个是基于大家比较熟悉的常规的SQL,另一个是基于比较非常规的JSON API。做的事情都是增删改查。效率上如果同样不做任何优化的话,MongoDB一般来说会有更高的并发执行能力。原因一个是基于内存的数据更新+异步落盘,另一个是采用的MVCC 乐观锁。
1.6 小技巧
- Mongo Compass官方的就是好用,大而全,我们还在用Mongo Booster,Mongo Compass中的Export To Language,帮我解决了大问题,在Mysql聚合查询语句翻译成MQL,再转换成Java 方式,快速高效,不用去翻MongoaTemplate API了
二、入门
2.1 介绍
- 重新定义OLTP数据库
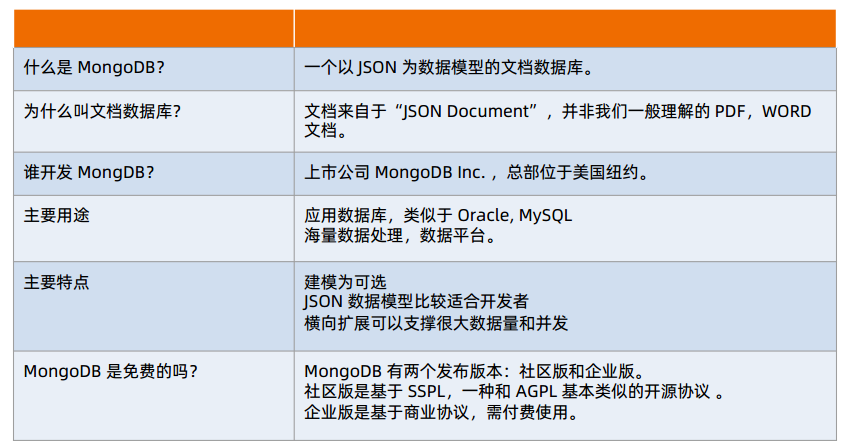
- 版本变迁:
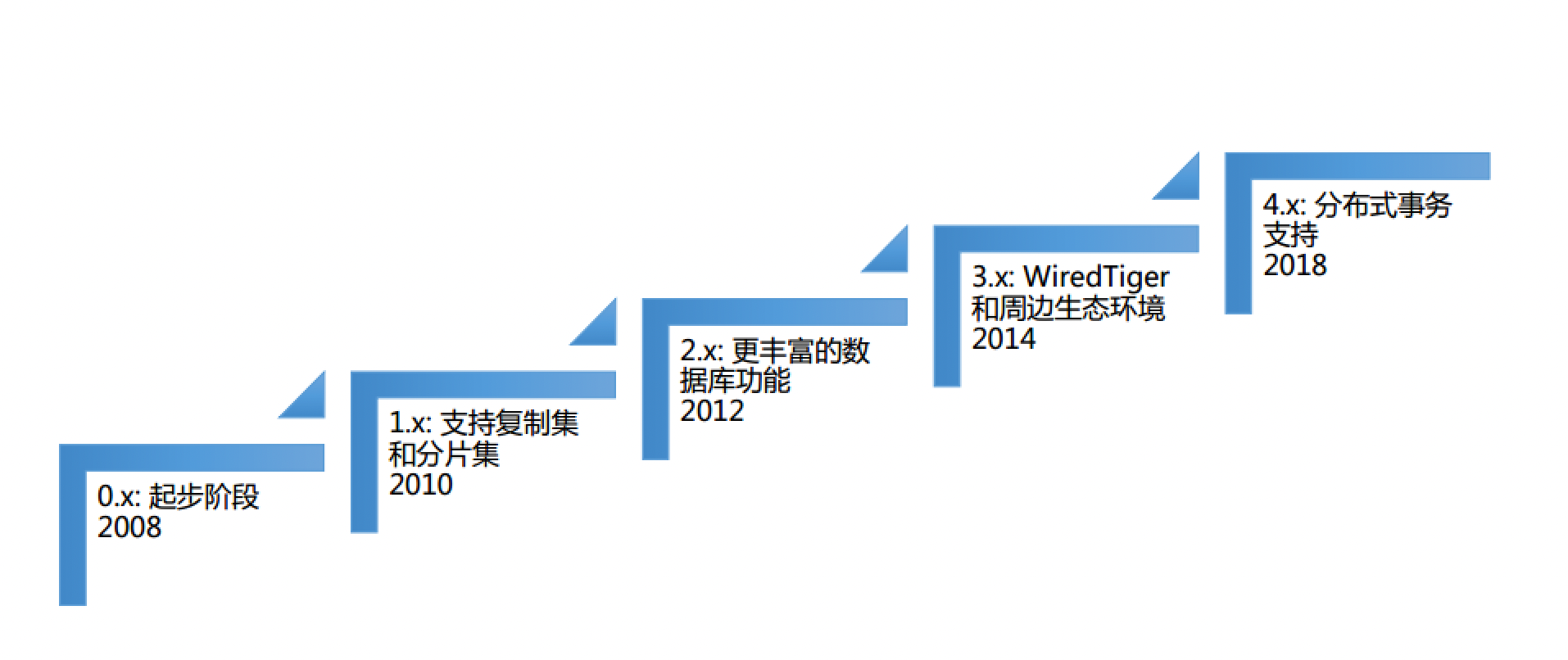
- 和关系型数据库对比
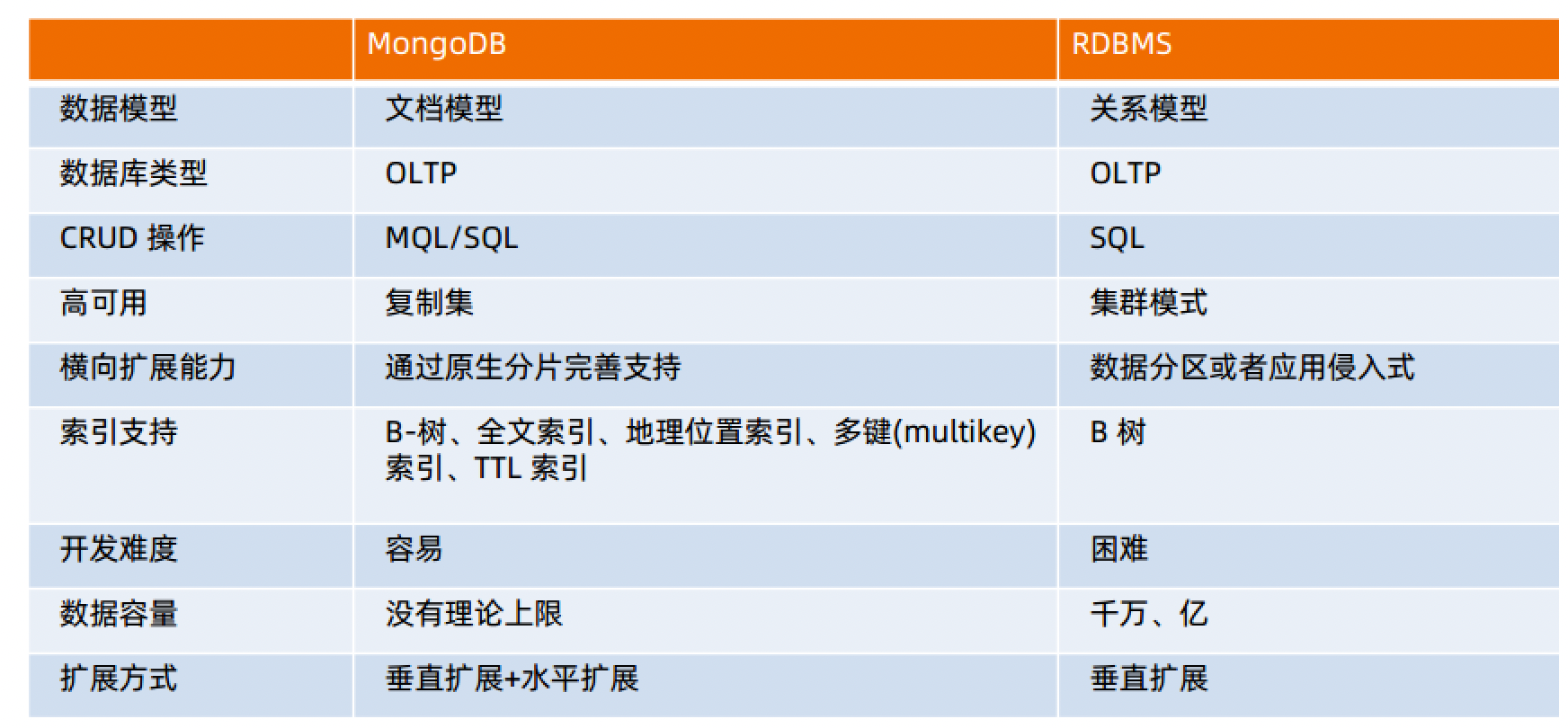
mongodb特色:
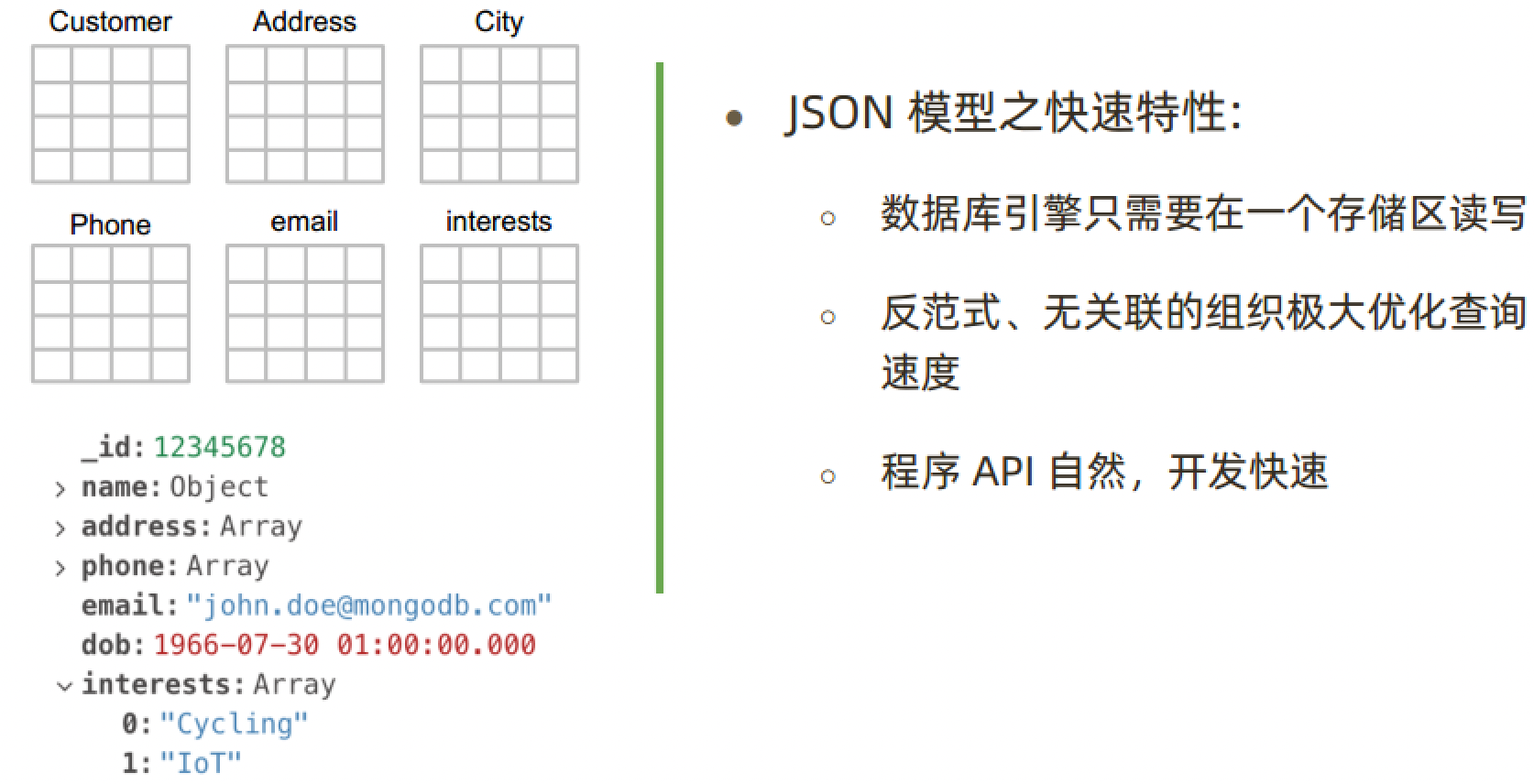
- 一目了然的对象模型
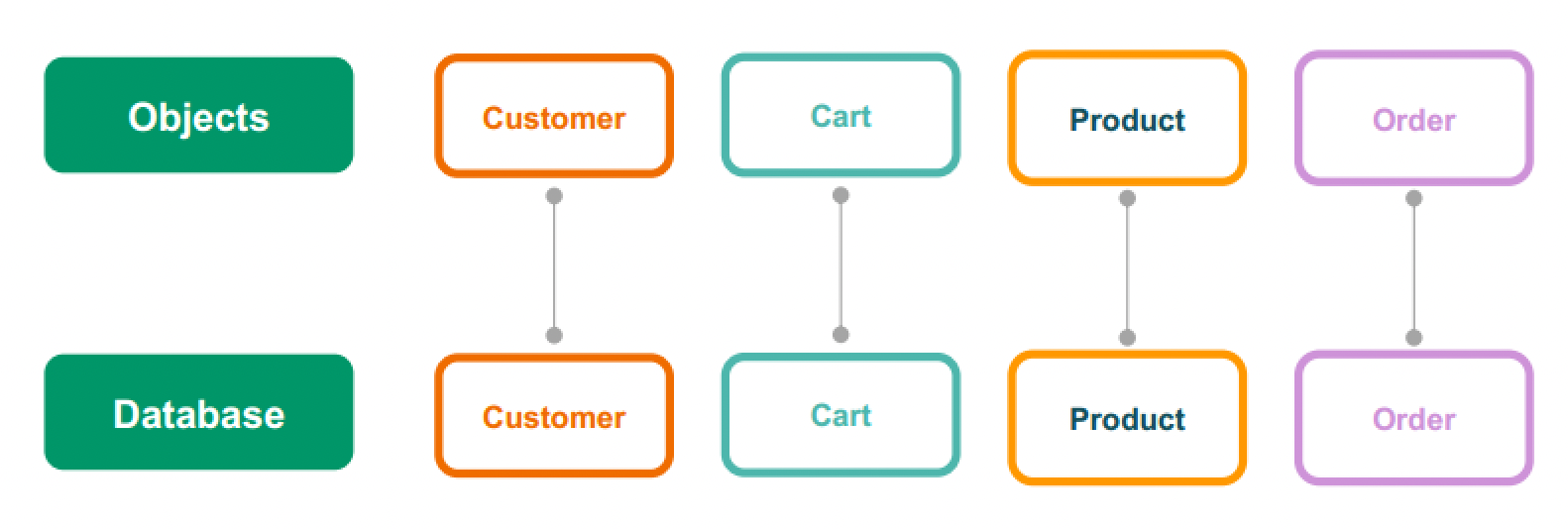
- 字段灵活多变

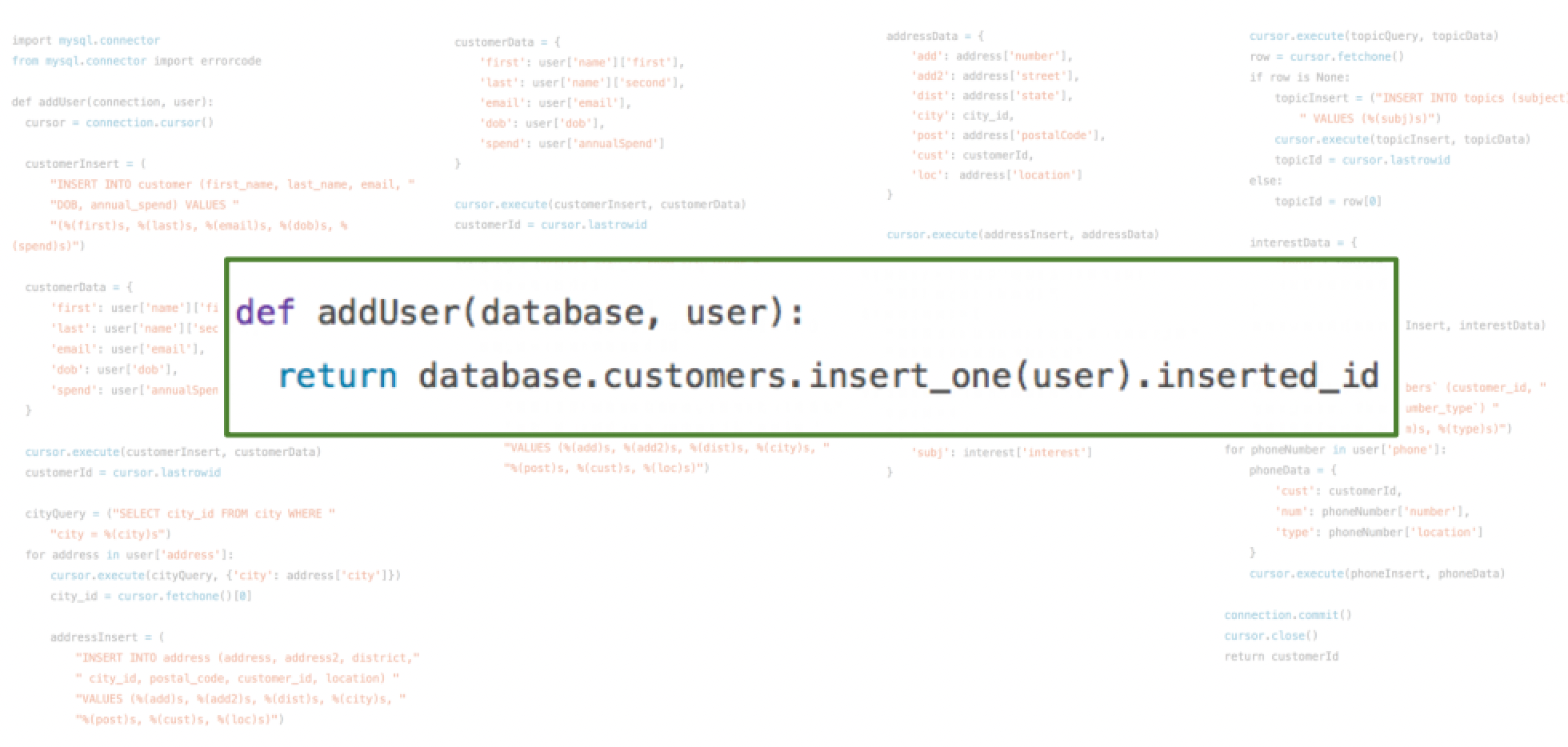
- 快速开发
- 代码简单
- 原生的高可用和横向扩展能力
横向扩展能力:

总结:

2.2 增删改查
插入
db.<集合>.insertOne(
) db.<集合>.insertMany([
, , … ])
1 | > db.fruit.insertOne({name:"apple"}); |
查询
关于 find
• find 是 MongoDB 中查询数据的基本指令,相当于 SQL 中的 SELECT 。
• find 返回的是游标。
find示例:
db.movies.find( { “year” : 1975 } ) //单条件查询
db.movies.find( { “year” : 1989, “title” : “Batman” } ) //多条件and查询
db.movies.find( { $and : [ {“title” : “Batman”}, { “category” : “action” }] } ) // and的另一种形式
db.movies.find( { $or: [{“year” : 1989}, {“title” : “Batman”}] } ) //多条件or查询
db.movies.find( { “title” : /^B/} ) //按正则表达式查找
条件查询:
$lt: 存在并小于
$lte: 存在并小于等于
$gt: 存在并大于
$gte: 存在并大于等于
$ne: 不存在或存在但不等于
$in: 存在并在指定数组中
$nin: 不存在或不在指定数组中
$or: 匹配两个或多个条件中的一个
$and: 匹配全部条件

 查询子文档:
查询子文档:
find 支持使用“field.sub_field”的形式查询子文档。假设有一个文档
1 | db.fruit.insertOne({ |
查询数组:
1 | // 插入数据 |
查询数组中的对象
1 | > db.movies.insertOne( { |
使用find搜索数组中的对象
在数组中搜索子对象的多个字段时,如果使用 $elemMatch,它表示必须是同一个子对象满足多个条件。考虑以下两个查询:
1 | > db.getCollection('movies').find({ |
控制find返回的字段
find 可以指定只返回指定的字段;
_id字段必须明确指明不返回,否则默认返回;
在 MongoDB 中我们称这为投影(projection);
db.movies.find({“category”: “action”},{“_id”:0, title:1})
删除
remove 命令需要配合查询条件使用;
匹配查询条件的的文档会被删除;
指定一个空文档条件会删除所有文档;
以下示例:
db.testcol.remove( { a : 1 } ) // 删除a 等于1的记录
db.testcol.remove( { a : { $lt : 5 } } ) // 删除a 小于5的记录
db.testcol.remove( { } ) // 删除所有记录
db.testcol.remove() //报错
更新
update 操作执行格式:db.<集合>.update(<查询条件>, <更新字段>)
以以下数据为例:
1 | > db.fruit.insertMany([ |
使用 updateOne 表示无论条件匹配多少条记录,始终只更新第一条
使用 updateMany 表示条件匹配多少条就更新多少条;
updateOne/updateMany 方法要求更新条件部分必须具有以下之一,否则将报错
1
2
3
4$set/$unset
$push/$pushAll/$pop
$pull/$pullAll
$addToSet
更新数组:
$push: 增加一个对象到数组底部
$pushAll: 增加多个对象到数组底部
$pop: 从数组底部删除一个对象
$pull: 如果匹配指定的值,从数组中删除相应的对象
$pullAll: 如果匹配任意的值,从数据中删除相应的对象
$addToSet: 如果不存在则增加一个值到数组
drop:删除集合
使用 db.<集合>.drop() 来删除一个集合
集合中的全部文档都会被删除
集合相关的索引也会被删除
db.colToBeDropped.drop()
dropDatabase:删除数据库
数据库相应文件也会被删除,磁盘空间将被释放
use tempDB
db.dropDatabase()
show collections // No collections
show dbs // The db is gone
问答
看3.6的官方文档,删除是用deleteOne, deleteMany,这跟remove有什么区分吗
remove是mongo shell下的命令。deleteOne deleteMany是程序语言下的API。做的是类似的事情。
elematch和分开写有什么区别?
$elemMatch表示一个数组元素同时满足两个条件 分开写表示一个元素满足一个条件,另一个元素满足另一个条件也算数 举例来说: db.test.insert({array: [{a: 1, b: 1}, {a: 2, b: 2}]}) db.test.find({“array.a”: 1, “array.b”: 2}); // 有结果,因为一个元素满足了a=1,另一个元素满足了b=2 db.test.find({array: {$elemMatch: {a: 1, b: 2}}}); // 没有结果,因为没有一个元素同时满足a=1并且b=2
投影(projection)里面是不是可以对某个属性的表示形式做变换呢?比如将一个整数属性(保存的为1970年1月1日开始的毫秒数)转为日期格式表示
数据格式转换是4.0才开始支持的功能,本质上所有的转换都可以用
$convert完成,但是转换为不同的数据类型时又有不同的简化版本。例如$toInt,$toBool,$toDate等。以下以使用最$toDate为例举例说明使用方式: // 测试数据 db.convertTest.insertMany([{ date: new Date().getTime() }, { date: new Date().getTime() - 3600000 }, { date: new Date().getTime() - 7200000 }]); 在$project中直接使用$toDate即可将epoch时间转换为日期类型: db.convertTest.aggregate([{ $project: { date: { $toDate: “$date” } } }]);db.fruit.find( { “from” : {country: “China”} } ),这个到底是在查什么呢?查一个json对象字段from的值是“{country: “China”}”吗?好像不是这样的。
这个表示查找一个JSON文档,这个文档有一个字段叫做 from, 并且 from字段的内容就是 {country: “China”} ,不多也不少。
mongodb删除了数据、表、数据库是没法恢复的么,有没有类似mysql有个日志记录的机制去回滚的?
mongodb有类似的oplog。但是那个要求你对全量的oplog都要保存,才能够从oplog里完全恢复被误删的表。
我在使用Robo 3T这个工具的过程中,对集合右键执行了 Drup Collection,执行之后,show collections 已经看不到那个集合,但是此前占用的存储空间没有变化。 请问下这个集合是否还存在? 如果存在是否可以恢复? 如果不存在,如何释放存储空间
在使用MMAP引擎的时候删除集合不会回收存储空间。在WiredTiger引擎是直接回收存储空间的。 你可以在shell下面再尝试下这个操作看看是否robo 3t相关。
从mongo库里的一个大集合(100多个G,6000万文档,每个文档有100多个字段)中通过聚合筛选出符合筛选条件(条件里有两个字段有索引,是机构和月份,不过索引可能不太好,重复值多 )的临时集合(几万-几十万),一般需要5分钟以上才能执行完。这种聚合操作有时候会在同一时间段执行二三十个,导致mongo库的CPU和内存会瞬间达到100%,并且会持续到这些查询执行完 才会释放资源。是否能有什么优化方法,降低CPU的消耗和提高查询速度?给其他字段加索引可能不行,因为每个查询的字段除了机构和月份外都可能不同。
机构和月份是否有做复合索引? 能否给更多的内存保证索引+用到的数据都在内存中? 使用readPreference 分散到多个节点去做
mongodb $in子句有长度限制吗?另外mongodb的 findMany返回的游标,会不会有内存溢出的问题呢?
理论上没有,只有bson 大小限制(16MB)。但实际上我用到1000的时候查询就很慢了。
2.4 聚合
MongoDB 聚合框架(Aggregation Framework)是一个计算框架,它可以:
• 作用在一个或几个集合上;
• 对集合中的数据进行的一系列运算;
• 将这些数据转化为期望的形式;
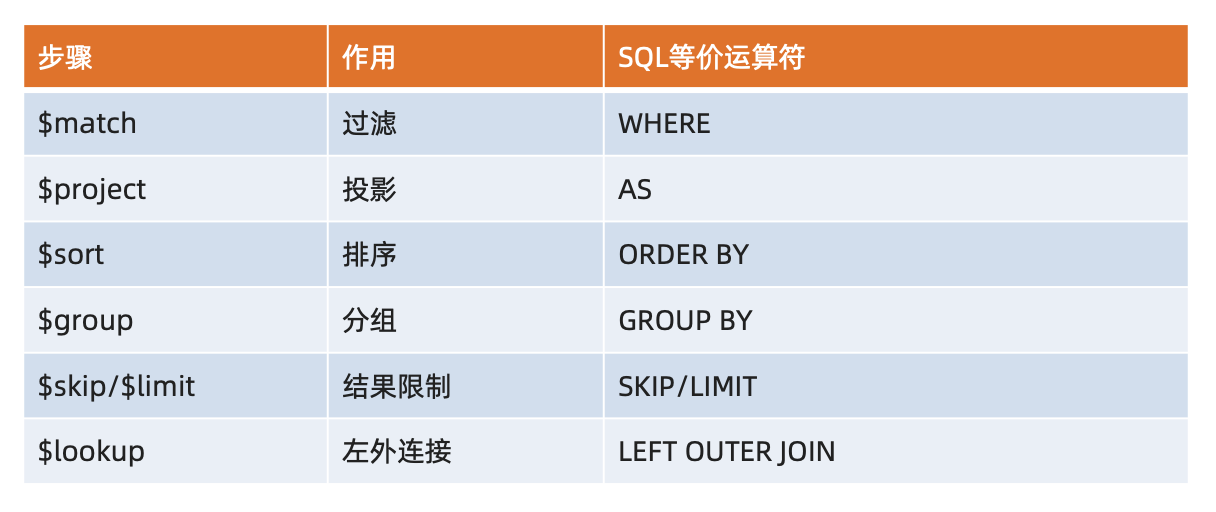
从效果而言,聚合框架相当于 SQL 查询中的:
• GROUP BY
• LEFT OUTER JOIN
• AS等
管道和步骤

聚合的基本格式:
1 | pipeline = [$stage1, $stage2, ...$stageN]; |
常见步骤:
常见步骤中的运算符

常见步骤:

聚合运算的使用场景

MQL常用步骤和SQL对比

MQL中特有的步骤$unwind

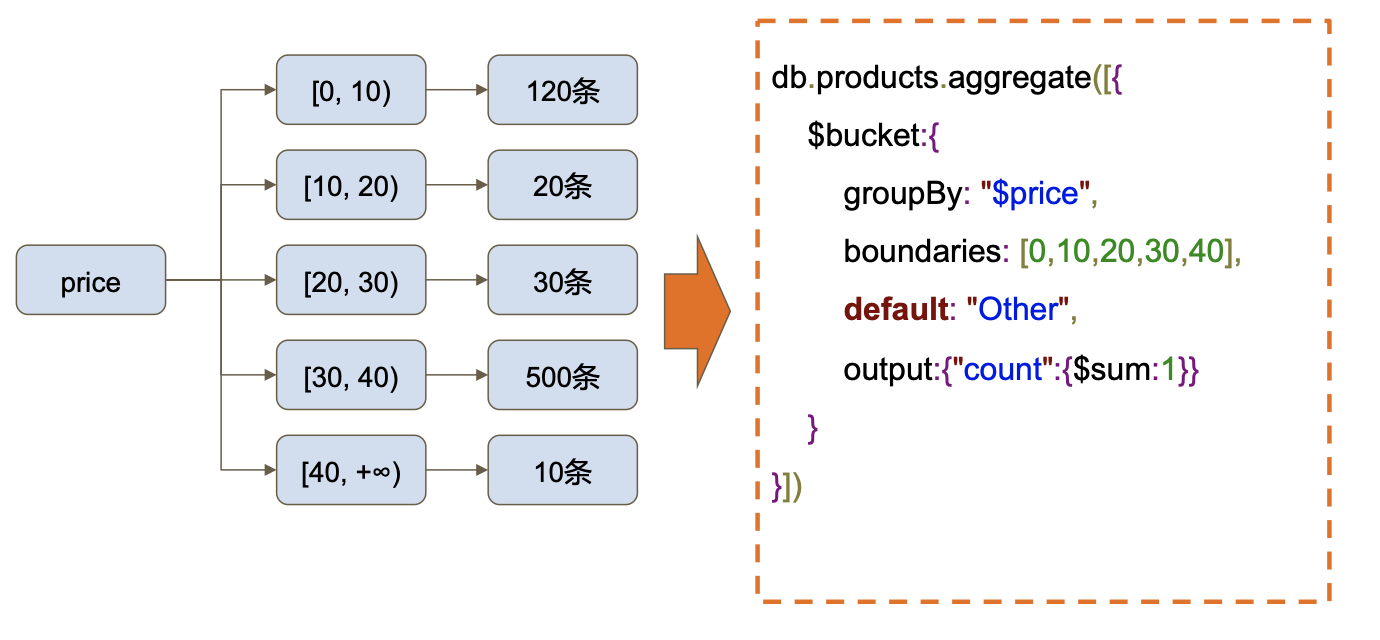
MQL中特有的步骤$bucket
MQL中特有的步骤$facet

实操
数据模型:

- 求所有订单的总销售额
1 | > db.orders.aggregate([ |
- 查询2019年第一季度(1月1日~3月31日)已完成订单(completed)的订单总金额和订单总数
1 | > db.orders.aggregate([ |
聚合框架可以帮助我们完成常见的分析应用类需求
MongoDB 聚合框架支持丰富的步骤运算符
通过 Compass 可以更加直观的来创建复杂的聚合计算管道
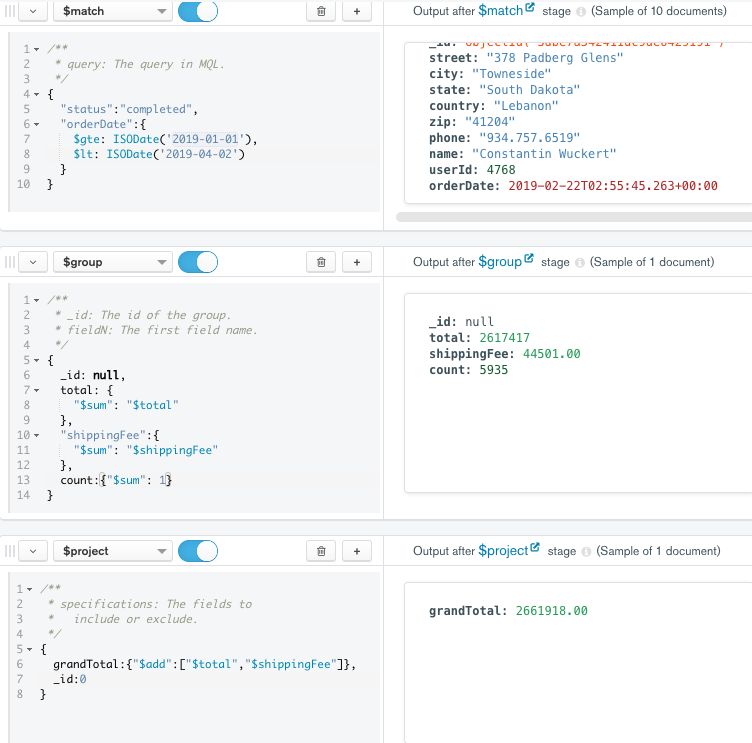
问答
复杂的聚合查询 一定要尽可能把所有的match放在在project投影之前,如果match出现在project之后 就无法享受索引加速了。 当然 还需要根据match字段 创建对应的联合索引。 我刚刚把一个复杂查询优化了 就是把几个match提前了 然后建索引,查询耗时从5秒降到1秒
请问mongo查询用explain分析查询语句,winningPlan选中的索引并非最优索引,用hint强制执行winningplan,执行是分钟以上,然后选择自己认为最有的索引执行,只需要几十秒。然而不用hint,直接执行也是几十秒,说明explain没有显示真正最优索引,请问这是什么情况
queryPlanner并不能保证100%找到最优的索引,所以才在必要的时候使用hint来强制指定。当你自己选了合适的索引执行以后,这个计划就会被cache,所以下次不用hint,可能也就是用了你这个cached的(最佳)索引
这个是我的一个推断。你可以清除下query plan cache再重新跑一下,看看是否还是能默认用到最佳索引
请教一下如果单表数据量有3亿,进行聚合统计比如count,效率怎么样
如果是无条件全表count,这个很快因为是实时计数的
带条件count取决于:1) 是否用到索引 2)你的数据是否都在内存 3)你的存储IO是否够快 - SSD vs SAS vs SATA 有很大差别
通常来说这种操作会需要几十秒到分钟级如果没有优化。
MongoDB的这种聚合功能,对数据量很大的时候,性能会不会很差,仍然有很好的性能表现吗
聚合功能的性能是比较差的
量大的时候要注意调优了 - 聚合操作也有explain功能,看是否用到合适的索引,以及执行计划是否合理等。关于explain我们在后续章节会详细介绍。
有一种常见的优化手段,Oracle/MySQL不太做得到的就是可以使用微分片(一个机器上部署多个分片)来提高聚合计算的并行能力。本来你只有一个数据库处理引擎来计算1亿条记录,我用10个微分片的话,我可以有10个处理引擎每个同时处理1000万,然后汇总结果数据。这个可以达到不错的性能提升效果。
lookup做join查询,两个集合的文档都大于10万条时,几乎就查不出来了,怎么优化呢
用于lookup 的字段,特别是 foreignField 在被lookup 表里面,必须要有索引。多半是因为这个
为什么在project里面,first_name前要加美元符号,在一般find里面不需要加
first_name要加美元符号,可以理解那是个变量, 实际的值要通过替换 first_name在文档中的具体值
find()操作里面的用到的first_name只是个key
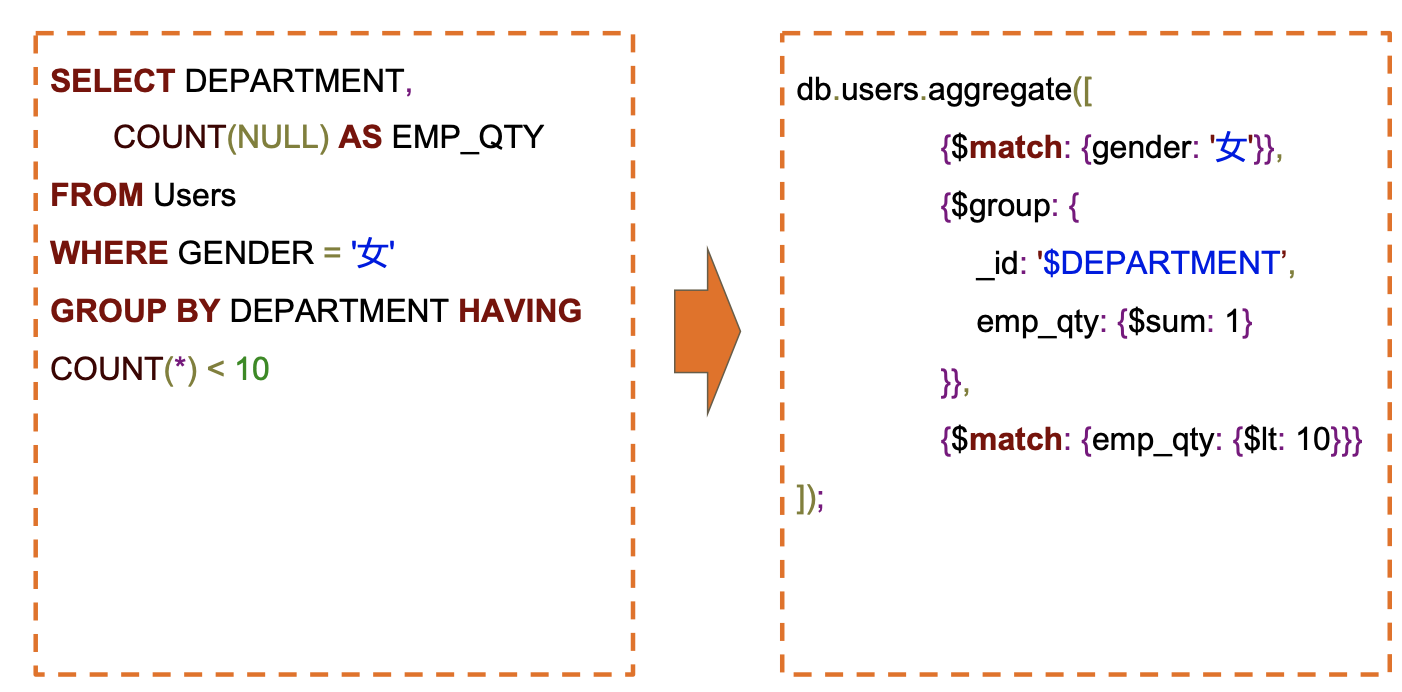
两个match的区别,另外emp_qty的sum设为1,是要做sum操作还是每次增加1, 如果设为2那统计出来的是人数的两倍吗
1
2
3
4
5
6
7
8db.users.aggregate([
{$match: {gender: '女'}},
{$group: {
_id: '$DEPARTMENT’,
emp_qty: {$sum: 1}
}},
{$match: {emp_qty: {$lt: 10}}}
]);第一个match是过滤原始集合的数据。第二个是针对group之后的结果再次过滤掉员工数量大于等于10的,只保留小于10个员工的部门。 第二个match没法放到前面,因为emp_qty在原始集合里不存在,必须等group之后才可以。
emp_qty: {$sum: 1}的意思是对group里面的每一条数据,值加1。 如果加2,自然结果就是两倍
有没有类似sumif的聚合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15没有sumif这个keyword,但是可以实现类似的事情,下面这个例子是只把>=10 的$a字段的值相加求和:
db.collection.aggregate([{
$group: {
_id: null,
total: {
$sum: {
$cond: [{ $gte: ["$a", 10] },
"$a",
0
]
}
}
}
}])请问 collection.mapReduce 与 collection.aggregate 的区别是?各自适用于哪些应用场景?
mapReduce已经是deprecated,基本不维护。Aggregation 是替代产品,用C++写,性能比较保证。但是mapReduce很灵活,可以写JS脚本。Aggregation要按照指定的语法,有些场景可能难以实现。 所以,如果能用agg做的,尽量用agg如果逻辑太复杂,就用MR
请教一下聚合查询的性能问题,能否结合您的业务场景自己数据量说明一下
这个范围很广。我们的客户中最大的有100TB的数据量上做聚合的(Amadeus)。当然那个是32台物理服务器和288个微分片的架构,比较复杂了。 通常来说MongoDB有可以在内存做计算的特性,如果你可以把你的数据都放在内存,那么聚合运算的性能大概率可以不错。 如果你有数千万数亿以上的行数要做扫描性汇聚,又是跑在机械盘,索引又没有优化,那么有可能是分钟级的聚合计算性能。
地区销量top1, 只取每个区域销量最大的那个返回该怎么写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//假设数据结构
{
areaCode: "Shanghai",
sales: 100
}
db.testData.aggregate([{
$sort: {
areaCode: 1,
sales: -1
}
}, {
$group: {
_id: "$areaCode",
topSales: {
$first: "$sales"
}
}
}]);数据结构和要求如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34{
"group":"A",
"status":"SUCCESS"
}
// 聚合期望结果
[{
group:"A",
SUCCESS:3
FAILURE:1
},
{
group:"B",
SUCCESS:1,
FAILURE:1
}
]
// 执行
db.test.aggregate([
{
$group: {
_id: "$group",
success: { $sum:
{
$cond: { if: { $eq: [ "$status", "SUCCESS" ] }, then: 1, else: 0 }
}
},
failure: { $sum:
{
$cond: { if: { $eq: [ "$status", "FAILURE" ] }, then: 1, else: 0 }
}
}
}
}
])如果我有若干年的毫秒级的价格数据,我想对每条数据增加一个字段,字段内容为当前时间到接下来1000毫秒之间的数据的价格字段的最大值,怎么实现
MongoDB里面貌似实现不了这么高级的计算,可能只能拉到内存里。这么大的量的话,要用到spark来做并发计算然后再把结果写回去mongodb。
接口需要给前端返回每日00:00:00 ~ 23:59:59这一天内,字段messageType分别为01 02 03 04 ,四种业务意义的请求数量,请老师明示怎么动态取每天的date,然后返回的结果分条显示当天24小时之内,不同值messageType得请求数量count(messageType)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44// 数据模型
{
messageType: '01',
date: ISODate("2019-01-01T01:15:42Z")
// 其他字段
}
1. 从日期中提取日期和小时。这里如果有必要,需要考虑时区问题。如果考虑时区问题,则需要3.6以上版本支持;
2. 按日期、小时分组聚合
db.test.aggregate([
// 过滤条件(如果有)
{
$match: {...}
},
// 映射出日期和小时
{
$project: {
date: {
$dateToString: {
date: "$date",
format: "%Y-%m-%d",
timezone: "+08:00"
}
},
hour: {
$hour: "$date"
},
messageType: 1
}
},
{
// 按日期、小时、messageType分组计数
$group: {
_id: {
date: "$date",
hour: "$hour",
messageType: "$messageType"
},
count: {
$sum: 1
}
}
}
]);我的数据库某张表有2.2M的数据,我需要从这些数据里面计算出想要的数据,比如某个产品的销售额度。这个用聚合会把数据库查崩么
如果计算的结果太大, 超过16MB,或者需要在内存进行排序或其他计算的时候超过100MB,聚合操作会失败。通常的做法是避免对非索引字段进行排序,或者使用allowDiskUse选项来突破100MB的限制。 另外,考虑在从节点上进行这样的聚合操作。否则会影响其他的数据库操作业务。
做聚合查询,希望把多个文档的同一字段合并在一起,这样使用第三方工具(matlab)读取时速度会明显加快,聚合过程中出现了BufBuilder attempted to grow() to 67108868 bytes, past the 64MB limit.’ 在网上查了下说是mongodb单个文档的大小限制。一般遇到这个问题该这么处理呢?感觉分成多个文档虽然可行但违背想方便的读取数据这个使用初衷了呢
这个是MongoDB的物理限制,目前除了分文档之外没有别的解决方案
2.5 复制集
作用
MongoDB 复制集的主要意义在于实现服务高可用
它的现实依赖于两个方面的功能:
数据写入时将数据迅速复制到另一个独立节点上
在接受写入的节点发生故障时自动选举出一个新的替代节点
在实现高可用的同时,复制集实现了其他几个附加作用:
数据分发:将数据从一个区域复制到另一个区域,减少另一个区域的读延迟
读写分离:不同类型的压力分别在不同的节点上执行
异地容灾:在数据中心故障时候快速切换到异地
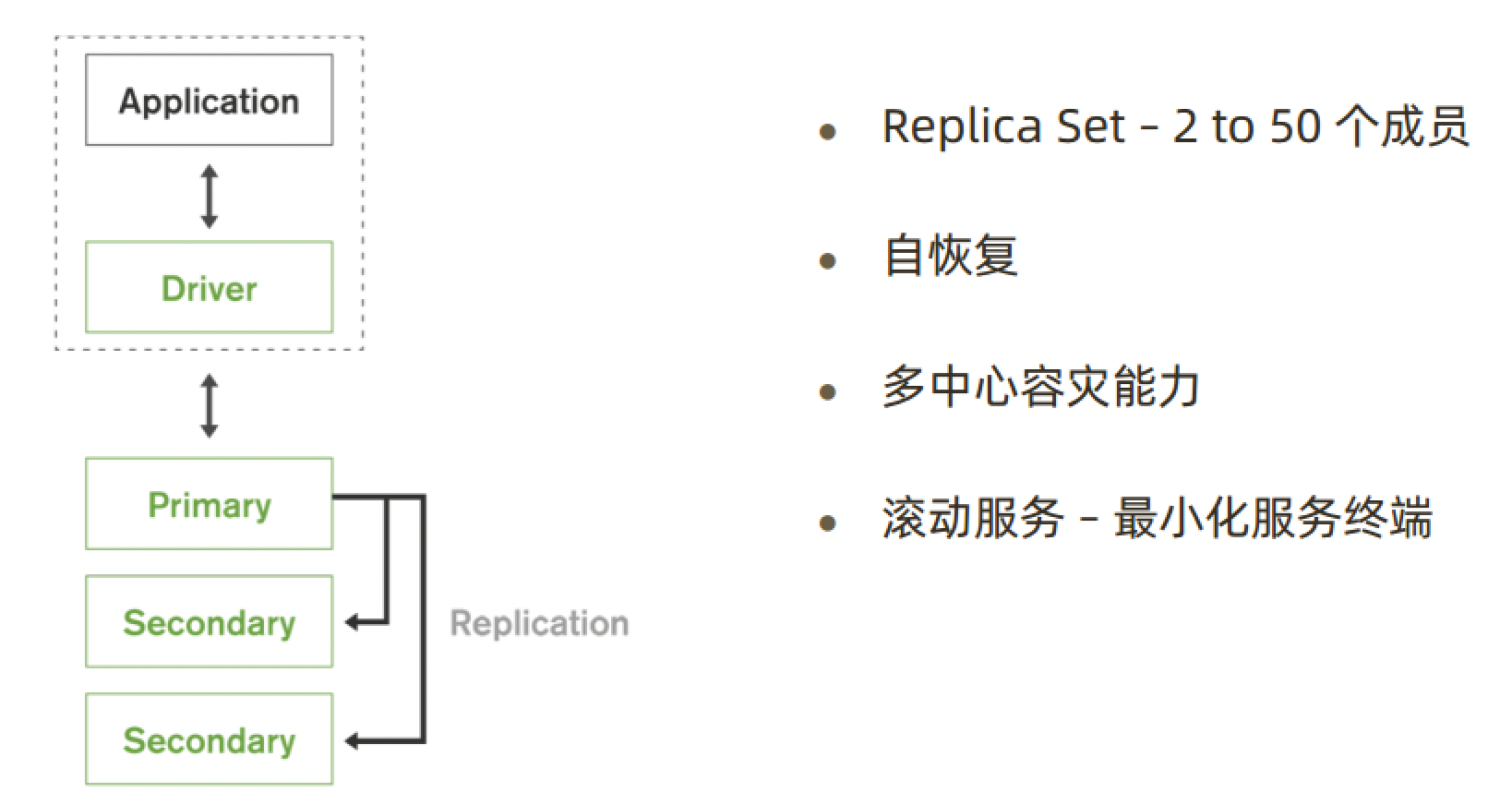
结构
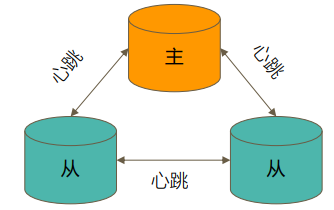
一个典型的复制集由3个以上具有投票权的节点组成,包括:
一个主节点(PRIMARY):接受写入操作和选举时投票
两个(或多个)从节点(SECONDARY):复制主节点上的新数据和选举时投票
不推荐使用 Arbiter(投票节点)

数据是如何复制的
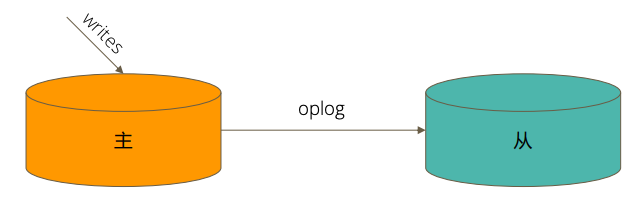
当一个修改操作,无论是插入、更新或删除,到达主节点时,它对数据的操作将被记录下来(经过一些必要的转换),这些记录称为 oplog
从节点通过在主节点上打开一个 tailable 游标不断获取新进入主节点的 oplog,并在自己的数据上回放,以此保持跟主节点的数据一致
故障恢复
具有投票权的节点之间两两互相发送心跳;
当5次心跳未收到时判断为节点失联;
如果失联的是主节点,从节点会发起选举,选出新的主节点;
如果失联的是从节点则不会产生新的选举;
选举基于 RAFT一致性算法 实现,选举成功的必要条件是大多数投票节点存活;
复制集中最多可以有50个节点,但具有投票权的节点最多7个
影响选举的因素:
整个集群必须有大多数节点存活;
被选举为主节点的节点必须:
- 能够与多数节点建立连接
- 具有较新的 oplog
- 具有较高的优先级(如果有配置)
常见选项
复制集节点有以下常见的选配项:
是否具有投票权(v 参数):有则参与投票;
优先级(priority 参数):优先级越高的节点越优先成为主节点。优先级为0的节点无法成为主节点;
隐藏(hidden 参数):复制数据,但对应用不可见。隐藏节点可以具有投票仅,但优先级必须为0;
延迟(slaveDelay 参数):复制 n 秒之前的数据,保持与主节点的时间差

复制集注意事项
关于硬件:
- 因为正常的复制集节点都有可能成为主节点,它们的地位是一样的,因此硬件配置上必须一致;
- 为了保证节点不会同时宕机,各节点使用的硬件必须具有独立性。
关于软件:
- 复制集各节点软件版本必须一致,以避免出现不可预知的问题。
增加节点不会增加系统写性能
搭建复制集
创建数据目录:
MongoDB 启动时将使用一个数据目录存放所有数据文件。我们将为3个复制集节 点创建各自的数据目录。
Linux/MacOS: mkdir -p /data/db{1,2,3}
Windows:
1
2
3md c:\data\db1
md c:\data\db2
md c:\data\db3
准备配置文件:
复制集的每个mongod进程应该位于不同的服务器。我们现在在一台机器上运行3个进程,因此要 为它们各自配置:
不同的端口。示例中将使用28017/28018/28019
不同的数据目录。示例中将使用:
1
2
3/data/db1或c:\data\db1
/data/db2或c:\data\db2
/data/db3或c:\data\db3不同日志文件路径。示例中将使用:
1
2
3/data/db1/mongod.log或c:\data\db1\mongod.log
/data/db2/mongod.log或c:\data\db2\mongod.log
/data/db3/mongod.log或c:\data\db3\mongod.log
下面每个db的配置需要改#标注的部分

启动进程:
Linux/Mac:
1
2
3
4mongod -f /data/db1/mongod.conf
mongod -f /data/db2/mongod.conf
mongod -f /data/db3/mongod.conf
注意:如果启用了 SELinux,可能阻止上述进程启动。简单起见请关闭 SELinux。Windows:
1
2
3
4
5mongod -f c:\data1\mongod.conf
mongod -f c:\data2\mongod.conf
mongod -f c:\data3\mongod.conf
因为 Windows 不支持 fork,以上命令需要在3个不同的窗口执行,执行后不可关闭窗口否则
进程将直接结束
启动后,三个mongodb 还不是集群,是独立的db
配置复制集:
通过hostname -f 查看hostname是否正常
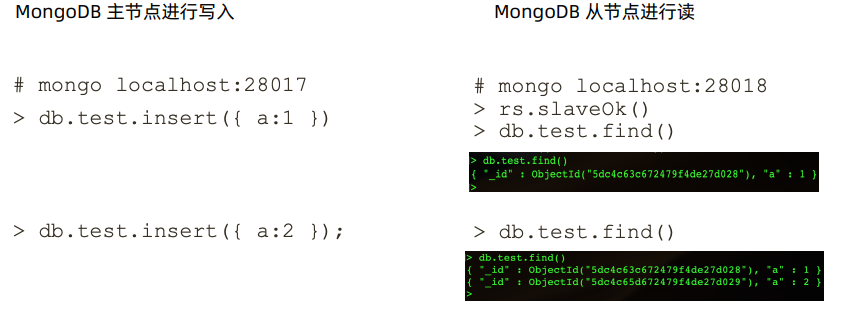
执行rs.initiat() 会变成SECONDARY,表示进入复制集的状态,再次从SECONDARY 变成PRIMARY
- rs.status()用来查看复制集的信息
- rs.add 添加其他的节点

验证:
总结:
● MongoDB 的生产环境要求搭建复制集
● MongoDB 复制集的搭建非常简单
● 实际环境要分三个物理(虚拟机)节点 (或以上)
问答
MongoDB官方好像是建议1主1从1arbiter。如果是1主2从,主节点挂掉后,两个从节点都投票给自己,这样僵持,不是会没法产生新的master吗?
“MongoDB官方好像是建议1主1从1arbiter” 请提供相应的文章。
主节点挂了以后,两个从节点的投票算法会防止你说的现象发生。具体来说,如果两个从节点条件完全一样,那么第一个主张的节点就获胜。如果两个从节点同时主张自己,那么两个人同时放弃,并用一个随机值等待一小段时间(数秒),然后重试。所以总有一个节点会在另一个之前选为主节点
通常怎样提高写性能
升级存储是最直接的方案,如PCIE + SSD,注意索引的数量:索引越多写入越慢;分片: 增加写的节点来提供并发
如果是奇数节点,那么主节点挂掉,不就变成偶数节点了
总数是看最初的配置,如你部署并配置了3个,虽然坏了一个,但是你的拓扑还是3节点, 按3节点的规则,剩下2个存活就可以正常工作。
复制集主从读写分离看起来很美好,但是如果对主从同步延时要求高,使用就很受限。 比如某些业务会写操作多,实时要求高的读场景多,这样主节点压力就很大,而从节点可以分担的业务场景非常有限
对。读写分离的读一般指的是对时效性要求不高的读场景。如果要求高一般都建议读主节点。如果主节点性能扛不住,这个时候就要采用分片集群来分担压力(读和写)。
建立3个独立的单机库,然后导入同一份数据,然后将3个节点设置为复制集模式,那么被设置为从节点的数据库里面的数据会被清空,然后再从主节点再同步回来吗? 2.如果3个节点通过公网ip地址互连,那么这中间的数据通信需要做安全防护吗?也就是这个时候节点间的通信数据被窃取,是否有泄露数据的风险
1)是的会重新同步。节点之间判断是否需要同步是根据local库里的元数据决定的。里面记录了节点同步的状态信息,并不是看你实际存储的数据
2)建议用SSL/TLS 加密链路就可以有效防止数据被窃取
主从复制是否会产生延迟,如果有延迟,那么常见有哪些因素会导致延迟,该如何避免或者降低延迟
主从复制会有延迟。常见因素: 1) 网络抖动 (没办法) 2)网络拥挤 (评估数据增量需求,给予足够的带宽) 3)节点之间延迟太长 4)主节点压力过大 (注意监控,压力过大要扩容) 5)从节点配置不均衡,低于主节点配置(尽量均衡)
太多的slave 数据节点。都从主节点拉oplog 是否反而增加了主节点的压力?反而让主节点性能变差了? 写主 读取从的这种配置是否还被推荐?什么场景适合这种
太多从节点会增加主节点的压力,大概是每增加一个节点会有10%左右的性能影响
主从读写分离还是比较常见的。所有读操作对数据时效(如报表型,或者历史数据)不高的都可以用从节点
请问 mongodb 的复制线程是主节点上的线程还是从节点上的线程?复制是主节点通知从节点还是从节点定时拉去呢
主从复制是由从节点的线程发起的。通过监听主节点的oplog表的变化,并把oplog的entries pull到从节点进行回放
oplog变化通知的方式类似于你在linux 下执行一个tail -f 命令,一旦你tail的文件(oplog)有变化,马上就会打印出来。或者在java里是类似于observable pattern
Mongodb2.4主从架构,从库复制从主库复制数据时会清空本地所有数据库吗?然后再同步?包括admin库
如果是因为同步滞后,超过oplog window大小,或者是数据库损坏,或者是刚加入主库,都需要执行initial syn的操作,这个就会清空本地库再同步
选举是发生在主节点故障时,那么它也会参与投票么
主节点故障如果是进程crash或者server crash,那么它当然无法进行选举。
如果故障是因为节点之间网络不通,那失联的主节点会自动降级为从节点。
如果是短暂故障马上恢复后,主节点(这个时候已经是从节点了)会重新加入选举,但是有个30秒的等待期
我们想使用此方式来提高mongodb的查询性能, 复制集采用一主两从,主节点使用memeory,从节点wiredtiger。 这样是否能够提供查询效率
这样做是OKAY的,当然要注意InMemory Engine是商业版产品需要付费
之前有人用RAMDISK方式来模拟InMemory,但是由于代码还是WT,所以和真正的InMemory Engine还是有些差别
复制集能基于数据库粒度吗? 公司项目数据库服务实例有多个数据库,但是只想迁移部分数据库. dump oplog选项也不支持数据库粒度, 但是阿里云DTS和tapData又能基于oplog做数据库粒度的毫秒级同步增量迁移,怎么做到的呢
复制集的设计原理是基于3个节点是完全等同的基础上(因为会主从切换)。当然,对于某些指定的非主节点(第4个以上,priority为0), 技术上实现库级/选择性同步是可以的的,只不过这个优先级不高,没有在mongo产品路线图里实现而已
投票节点为什么不建议用?我看有的书上,如果是偶数的时候,又增加一个投票节点,这样就变成奇数了,比如3个数据节点,2个投票节点。mongo为什么要设计投票节点;1 从节点之间出现心跳不通,但是都和主节点是通的,这个会出现问题么?是不是网络结构部署有问题?
1)投票节点的最早设计初衷:需要奇数节点满足一致性协议,但同时又想节省资源。为何不建议用?降低的可用性(丢一个数据节点后风险很高),无法使用更高的writeConcern(后续章节会讲)来保证在主从切换的时候保证不丢失数据
2) 这种现象出现的可能性不大,你可以尝试下画下网络拓扑,具体到物理层链路。如果真的出现了,应该是可以继续工作的。
请教一下采用多副本集后,主节点写,其他复制集读,但有时候主会切换成其他副节点,导致访问mongodb的端口变化,调用程序无法连接上之前主节点进行写入操作,前端调用程序该如何处理
“但有时候主会切换成其他副节点” 你是在同一台服务器上起了几个不同端口的实例?这样的复制集/副本集是没有意义的。 这种场景是常见的,在mongo世界里。你的连接串要同时包含3个节点的IP:PORT,这样在切主的时候mongo的驱动会自动连到下一个主节点,你的应用程序无需处理。
oplog 类似mysql row格式log mongo rs.printSlaveReplicationInfo()总能监控到几秒的延时, 读写分离的架构对于mongo如何使用呢
那个命令可能不是太合适,用来做精确判断。考虑用个脚本,来做比较准确的判断会好一点,基于change stream或者oplog
第一个问题:关于复制集这块的secondary是怎么从主库来来取oplog的,实现的细节是什么?想了解这块的出发点就是作为dba的话,会经常遇到一些生产问题,需要从原理上解决问题? 第二个问题:我有一个副本集,现在对一个secondary进行了物理的热备,之后,想把这个节点加入现有集群,是只需要配置参数文件,add加入副本集就可以吗?如果可以加入副本集的话,他是通过哪个集合来判断从哪个时间点开始来取oplog的
第一个问题你可以先看下这篇博客: https://www.cnblogs.com/Joans/p/7723554.html 第二个问题:可以的,但是要通过对local库下面的一些表做个手脚。如果你用MongoDB的Ops Manager的话,它就提供这种方法来快速恢复一个从节点。 https://docs.opsmanager.mongodb.com/v1.4/tutorial/use-restore-to-seed-secondary/ 其中关键的集合是system.replset 以及oplog.rs。 system.replset必须包含对应的配置(和其他节点一致)和时间戳。oplog.rs必须包含至少一条和主节点oplog一样的记录用来匹配同步点。
我们的生产环境只有一台服务器,但有2个硬盘。做一主一从副本集,有意义吗
意义不是很大,你crash了一个进程,另一个进程也是没法正常服务(需要3个节点才可以有HA)。硬盘的容错直接用RAID就可以
从节点是主动监听主节点的op log并拉取吗? mongo 选举的时候,怎么知道集群中一共有多少节点?还有就是自己是和大多数节点互通的
1: 是的。 2: 配置。开始搭建集群时候就要配置一下(或者通过add方法增加节点)
复制集和分片机制有什么区别?我们可以对数据分片到不同机器上的同时保留复制集吗?部署配置方式有区别吗
复制集提供高可用,分片集在此基础上横向扩充,增加系统对数据量/并发量的支持。分片集由2个或多个复制集组成
如果要在 10 亿数据中查找摘要包含 MongoDB 的记录,{summary:/MongoDB/},要求 1000 毫秒内返回结果,应该怎么玩?一定要单机配置很好的集群吗?单机配置一般,个数可以无限增加可以玩吗?分片是为了解决这类问题吗
这里面最关键的是内存大小。 考虑为summary建一个covered index,然后保证你的索引能够装在内存里 (所有索引大小加起来要小于物理内存的一半那样)。 如果你用分片的话,比如说4个分片,那每个分片只需要处理2.5亿(在2.5亿里寻找,4个分片同时进行),理论上肯定更快了。但是最终还是要看你总的内存的数量
之前试过用mysql 做读写分离,开了binlog做主从同步。遇到一种情况,主库写太频繁(load file操作,没有事务),从库同步延迟越来越大。oplog的原理是否也是记录成文件之后传输到从节点,由专门线程回放?mongodb是否也会出现这种问题
oplog 和 binlog类似。并且在压力超大的时候,也有可能在从节点造成一些延迟。当然mongodb可以用多线程同时来回放
我在搭建集群的过程中遇到一个问题。 如果我集群中的所有节点都设置了密码,在使用rs.add(“host:port”)时会报没有权限。此时我该如何解决呢
没有为各个节点配置KeyFile,或者 2. 启用认证之后没有创建管理员账户。rs.add()需要权限才能执行
请问一下,我按照你的操作是没有问题的。但是在复制集搭建成功后做如下操作,从节点却获取不到数据时怎么回事呀
不能用local 库。那个是系统保留的。用任意其他库都可以。如 use test
如果在从节点强制执行副本集reconfig,force:true,会引发副本集的全量同步吗
reconfig 原则上不会触发全量同步,除非是加入新的节点
2.6 MongoDB全家桶
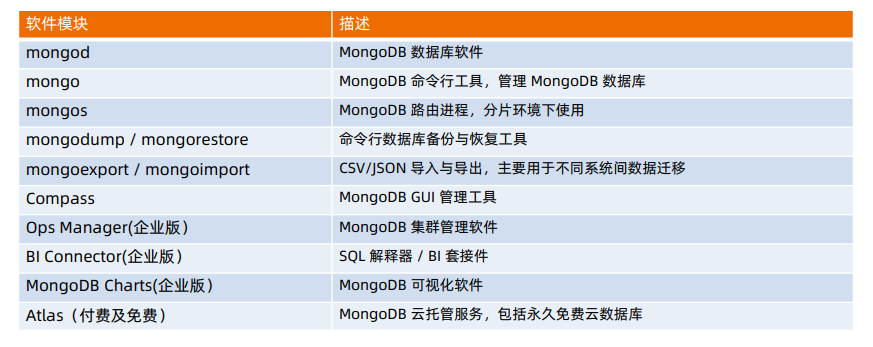
mongodump / mongorestore
类似于 MySQL 的 dump/restore 工具
可以完成全库 dump:不加条件
也可以根据条件 dump 部分数据:-q 参数
Dump 的同时跟踪数据就更:–oplog
Restore 是反操作,把 mongodump 的输出导入到 mongodb
1 | mongodump -h 127.0.0.1:27017 -d test -c test |
公有云托管服务
BI Connector
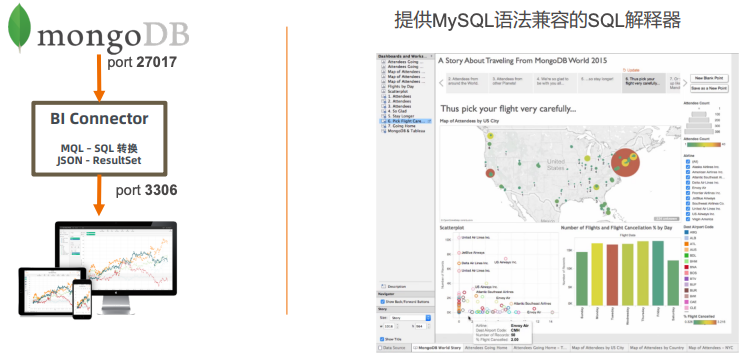
Ops Manager - 集群管理平台

MongoDB Charts

问答
- 讲到MongoDB Ops Manager 集群管理平台时,说到该软件支持 分片集群的备份。请问分片集群的备份是什么意思?mongodump 做不了吗
mongodump 能做全量备份,但是做不到一致性备份。比如说,你想要一个半夜12点的备份,希望这个备份能够还原那个时间点的分片数据库的准确状态。事实上,当你12点开始跑的时候,可能要跑几十分钟到数小时才能备份完。这个时候又有持续的写入(可能会在备份里,可能不会在,取决于mongodump的读取顺序),所以你这个备份是属于不一致状态。 Ops Manager有自己独特的机制来保证一个备份的多个分片之间数据是在一个时间点上一致的